Research Projects
Adaptive Multi-Human Multi-Robot Systems
Multi-human multi-robot (MH-MR) teams are emerging as promising assets for tackling high-stakes and large-scale missions. The simultaneous collaboration of multiple humans and robots with diverse capabilities offers tremendous potential, but also introduces significant coordination challenges. This project focuses on adaptive teaming strategies, human state reasoning, and dynamic adaptation mechanisms.
Adaptive Teaming Strategies
Develop advanced Initial Task Allocation (ITA) strategies that account for team heterogeneity during the teaming stage. This involves dynamically initializing task distribution, assigning roles, and defining collaboration patterns by considering the diverse capabilities of both humans and robots under varying task requirements. The objective is to harness this heterogeneity constructively, forming complementary human-robot pairings or chains that optimize overall team performance.
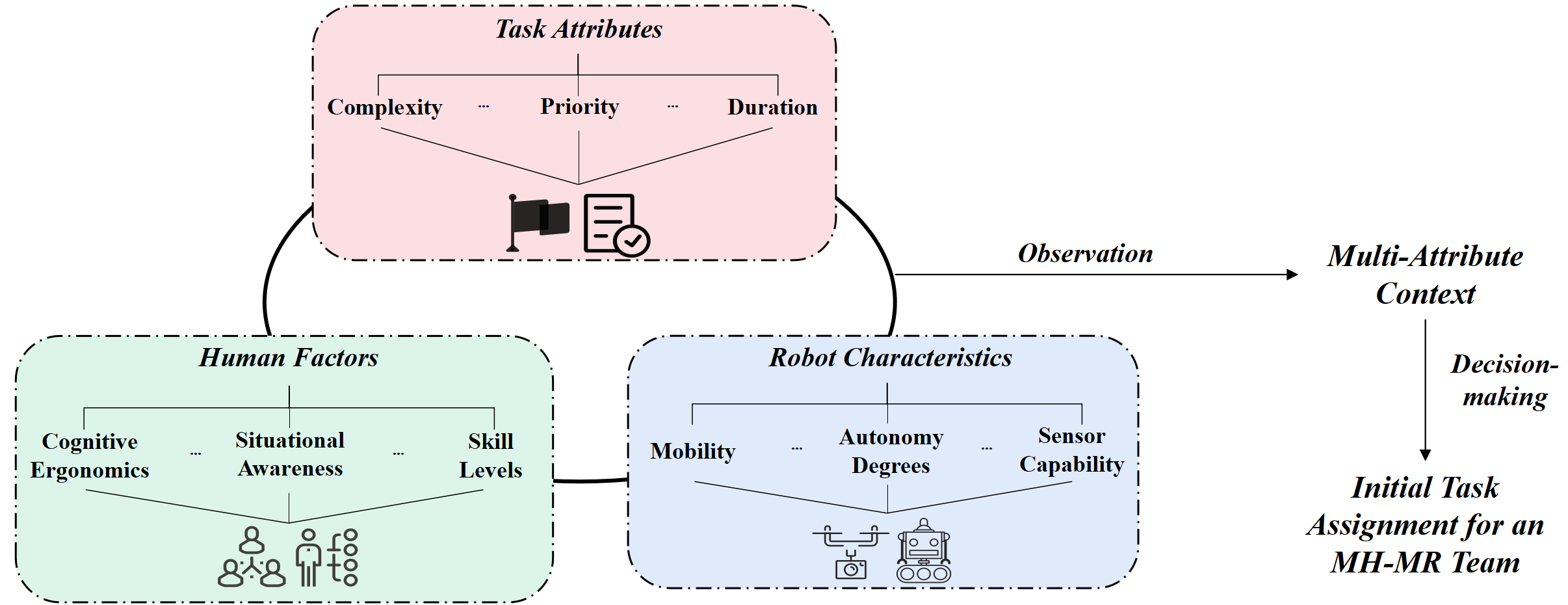

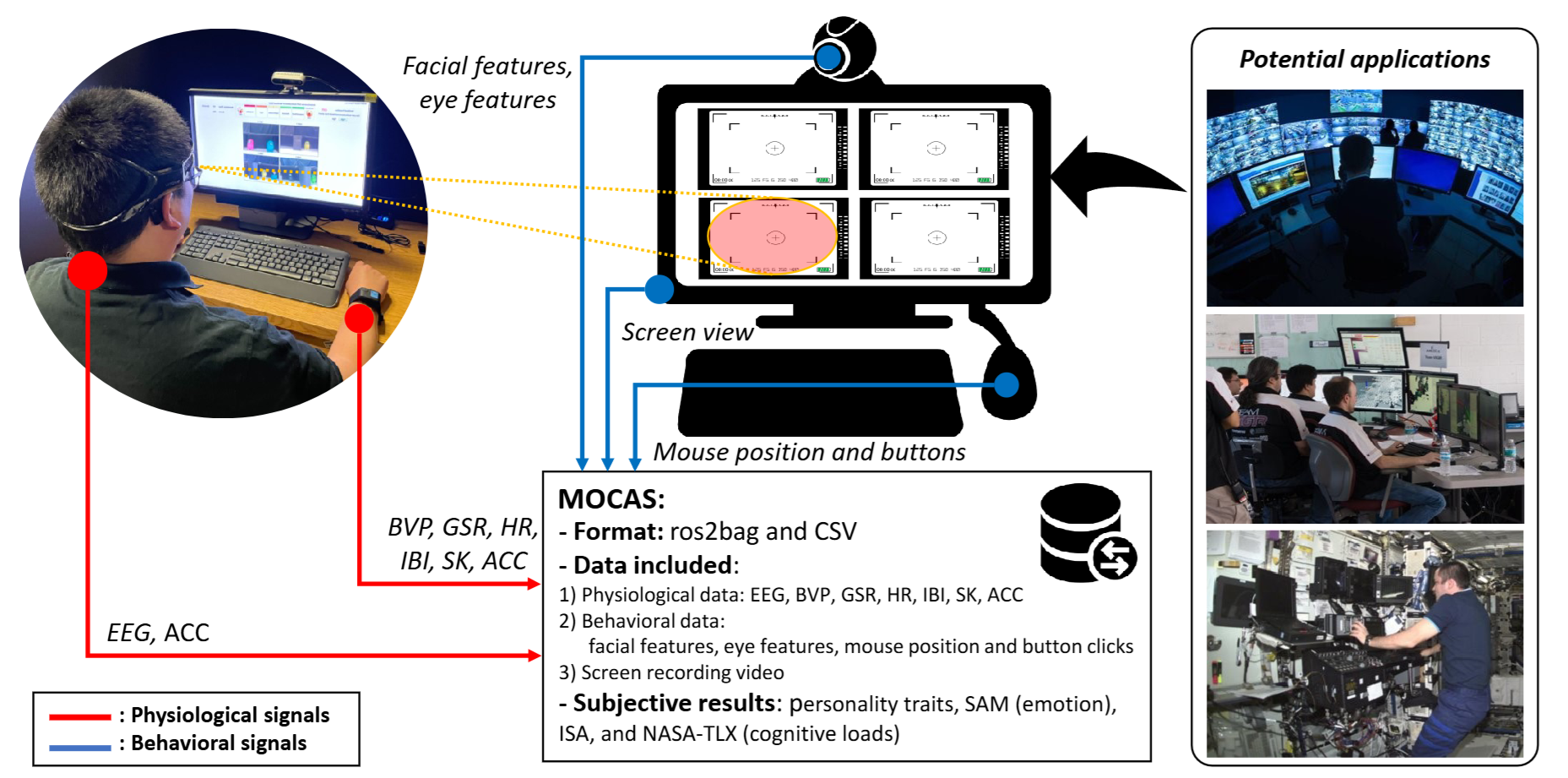
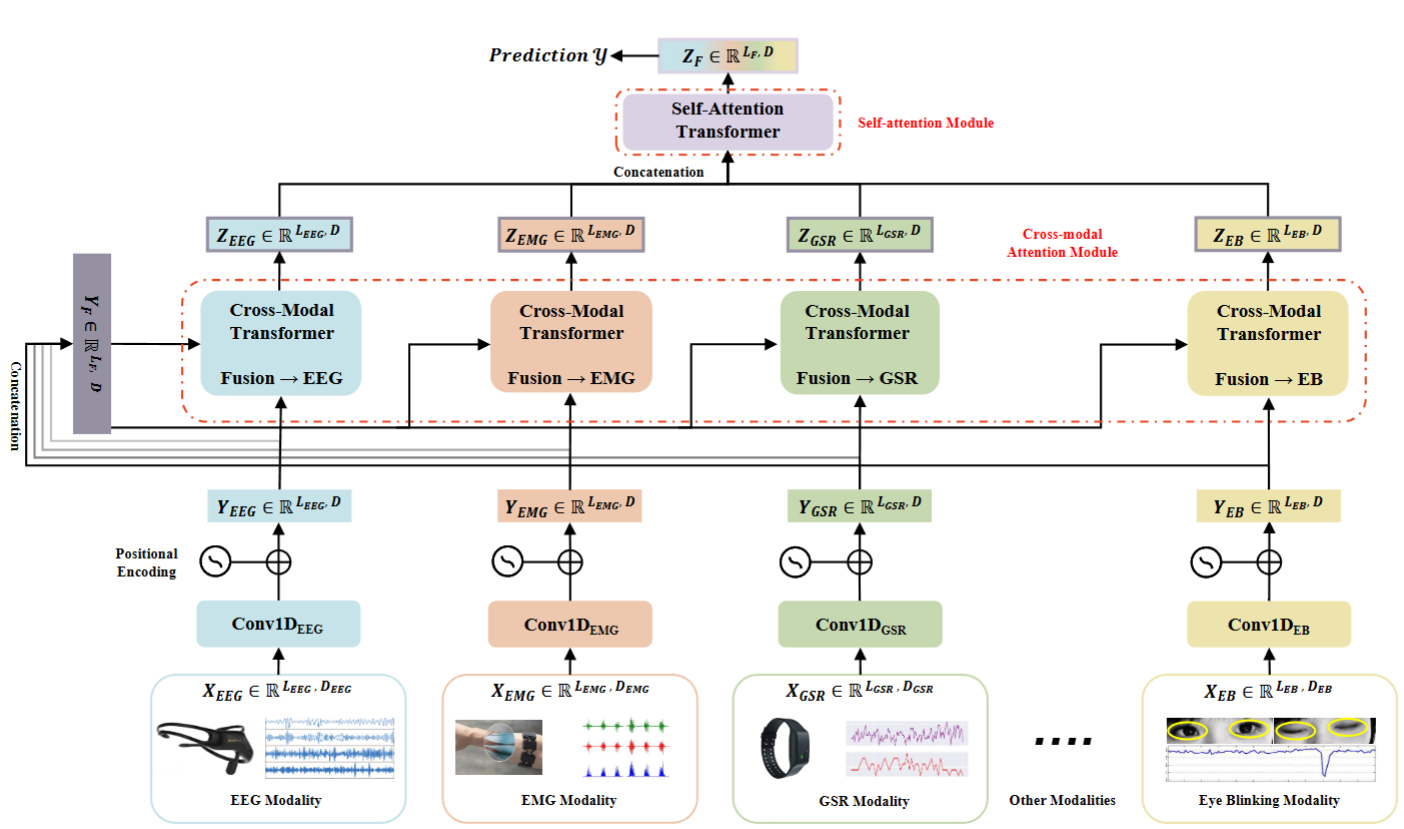
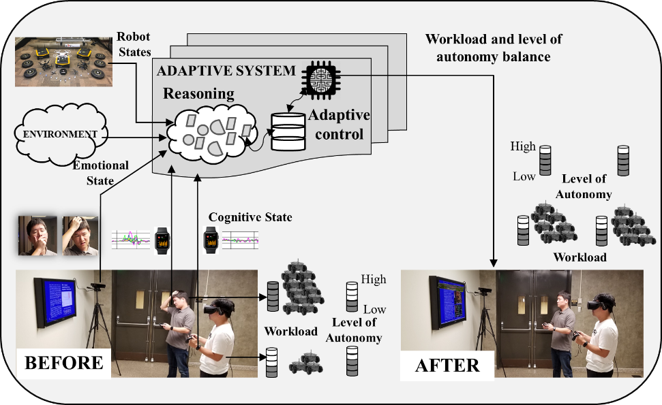
Multimodal Human State Reasoning
Investigate the dynamics of human states, including cognitive load and emotion, and develop models that provide real-time assessments using multimodal physiological and behavioral signals.
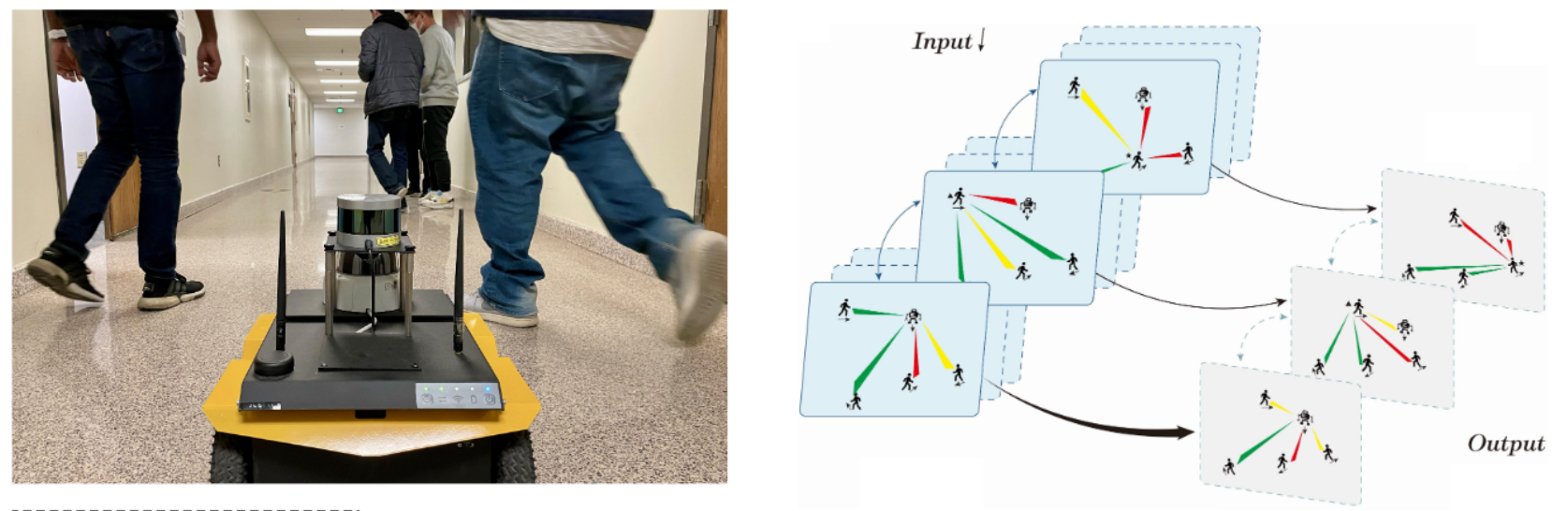
Dynamic Adaptation Mechanisms During Operation
Develop adaptive mechanisms to re-adjust team collaboration patterns and re-allocate tasks within the team according to perceived changes in human states, robot conditions, and evolving task progress.

Human-in-the-Loop Robot Learning for Personalized HRI
Individual preferences often transcend measurable factors—people with similar capabilities may still prefer different interaction patterns. This project develops efficient human-in-the-loop, preference-based robot learning algorithms to personalize robot behaviors, enhancing user satisfaction and interaction quality.
Preference-based Robot Learning
We specifically investigate: how to minimize the amount of human feedback required while maximizing learning outcomes; how to accurately model human preferences toward robot behaviors; and how to allow rapid and effective adaptation of robot policies based on preference data.


Socially-Aware Robot Navigation
Socially-aware robot navigation (SAN) involves optimizing a robot's trajectory to maintain comfortable spatial interactions with humans while efficiently reaching its goal. This requires balancing safety, efficiency, and social etiquette in varied environments.
Modeling Complex Social Interactions
Our work focuses on developing algorithms that better encode and interpret the intricate social dynamics across humans and robots within varied environments. This involves leveraging advanced deep learning techniques to understand human behaviors in diverse settings, enabling robots to navigate with a deeper awareness of social nuances.